Giriş
Bu yazıda, Maaş Anketi Analizi çalışmasının özeti sunulmaktadır. Amaç; anketten elde edilen verilerle teknoloji sektöründe maaş dağılımlarını, deneyim ve seviye ile ilişkisini, çalışma biçiminin (remote/hibrit/ofis) etkisini ve kullanılan teknoloji/araçların maaşa olan katkısını (ROI) sayısal ve görsel olarak ortaya koymaktır.
Proje; veri temizleme, özellik standardizasyonu, istatistiksel hipotez testleri, zengin görselleştirmeler ve Streamlit ile etkileşimli bir mini dashboard’tan oluşuyor. Bu yazıyı, portföyümde projeyi hızlıca değerlendirmek isteyenler için hazırladım; kaynak kodlara ve çıktılara repo içinde bağlantı verdim.
Veri ve Kapsam
- Örneklem: Sadece 2025 anket yanıtları (temizleme sonrası anlamlı örneklem korunmuştur). 2024 verisiyle karşılaştırmalı analiz, sonraki sürümde planlanmaktadır.
- Hedef değişken: Ortalama Maaş (salary_numeric) ve toplam tazminat (standartlaştırılmış)
- Boyutlar: Seviye, rol, cinsiyet, çalışma biçimi, şirket konumu, istihdam türü, kullanılan teknoloji ve araç setleri
Metodoloji (Kısa Özet)
-
Veri Temizleme ve Standartlaştırma
- Eksik/değersiz kayıtlar ele alındı; kategoriler standardize edildi, Ortalama Maaş (salary_numeric) metriği üretildi ve normalize edildi.
-
İstatistiksel Analiz
- Gruplar arası farklar için parametrik/parametrik olmayan testler (ör. t-test, ANOVA/kruskal) uygulandı.
- Etki büyüklükleri ve güven aralıkları raporlandı.
-
Görselleştirme
- Boxplot, heatmap, violin plot, line plot, barplot.
- Etkileşimli örnekler (Plotly) ve statik görseller (Seaborn/Matplotlib).
-
ROI Analizi (Teknoloji ve Araçlar)
- Teknoloji/araç kullanımının maaşa marjinal katkısı, rol ve deneyim düzeyine göre incelendi.
- ROI metriği, kontrol değişkenleri ile birlikte karşılaştırmalı olarak yorumlandı.
-
Raporlama
- Bulguların PDF raporu Overleaf üzerinde LaTeX ile yazıldı.
Öne Çıkan Bulgular
- Deneyim ve Ortalama Maaş: Deneyim arttıkça ortalama maaşta anlamlı artış gözlenmektedir.
- Seviye Dağılımı: Üst seviyelerde dağılım genişler; pazar segmentasyonu ve sorumluluk farklılıkları etkilidir.
- Çalışma Biçimi: Remote/hibrit modeller, bazı rollerde daha yüksek medyan değerlere sahiptir.
- Lokasyon Etkisi: Şirket lokasyonu, ortalama maaş varyansını anlamlı ölçüde etkiler.
- Work Mode x Location: Office, Remote ve Hybrid’in tamamına kıyasla daha düşük ortalama maaş seviyeleriyle ilişkilidir.
- Rol–Teknoloji Eşleşmeleri: Bazı teknoloji kombinasyonları ücret avantajı sağlar.
- Araç/Stack ROI: Belirli araç setleri (özellikle frontend ve data araçları) seçili rollerde daha yüksek getirilerle ilişkilidir.
Not: İstatistiksel anlamlılık ve etki büyüklüğü metrikleri, p-değerine bağımlı kalmadan yorumlandı; örneklem büyüklüğü ve pratik önem birlikte değerlendirildi.
Görsellerden Birkaç Örnek
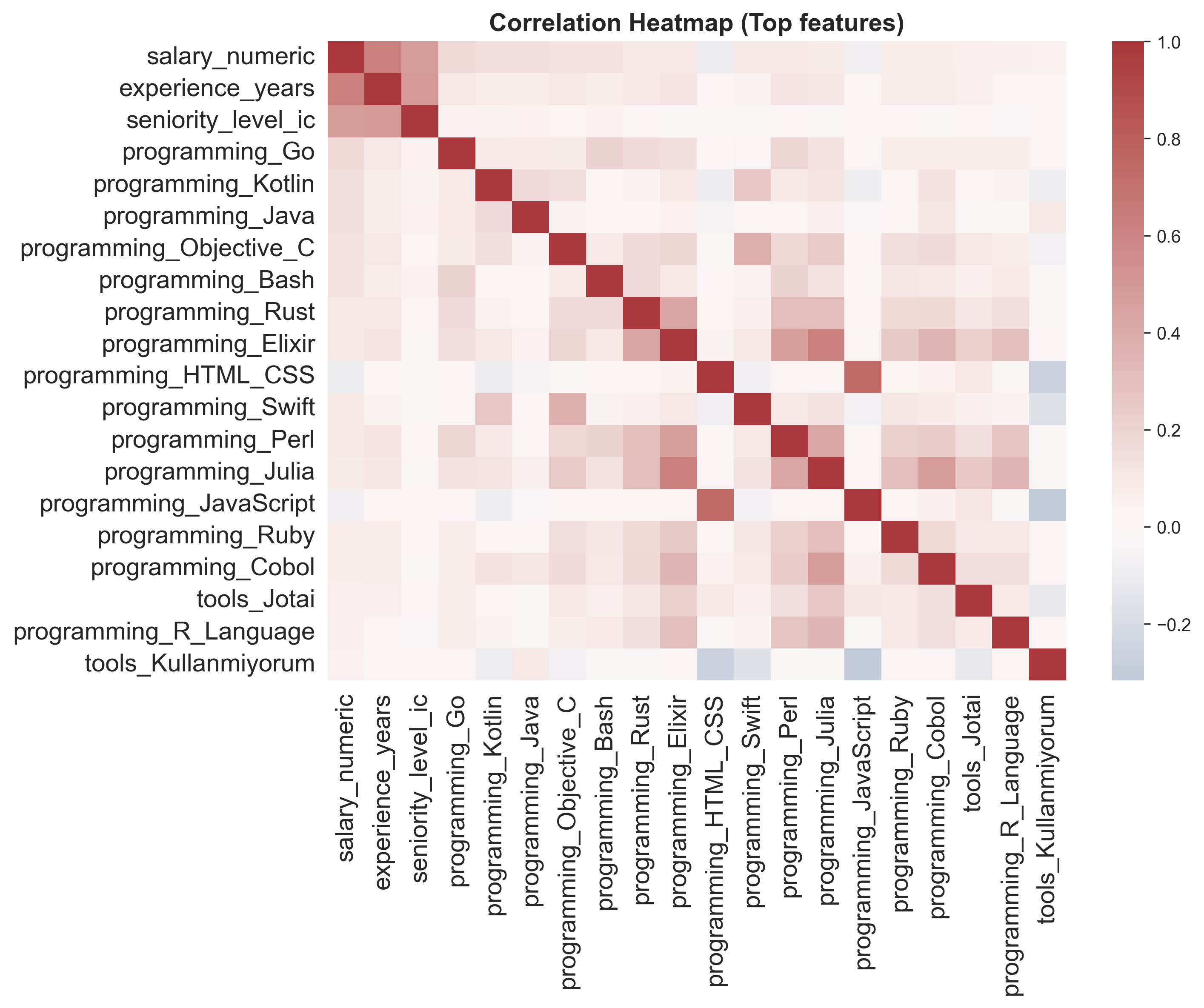
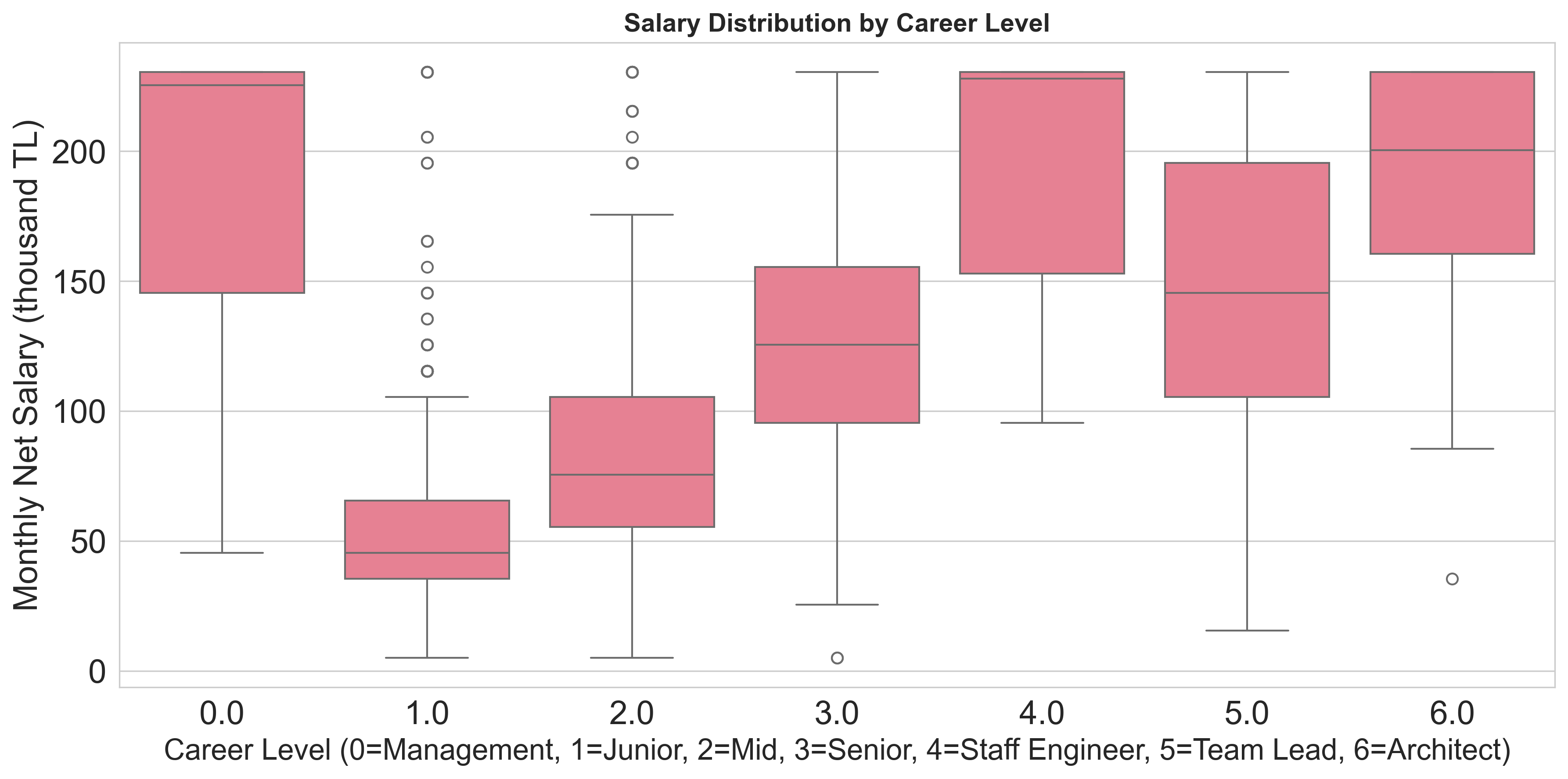
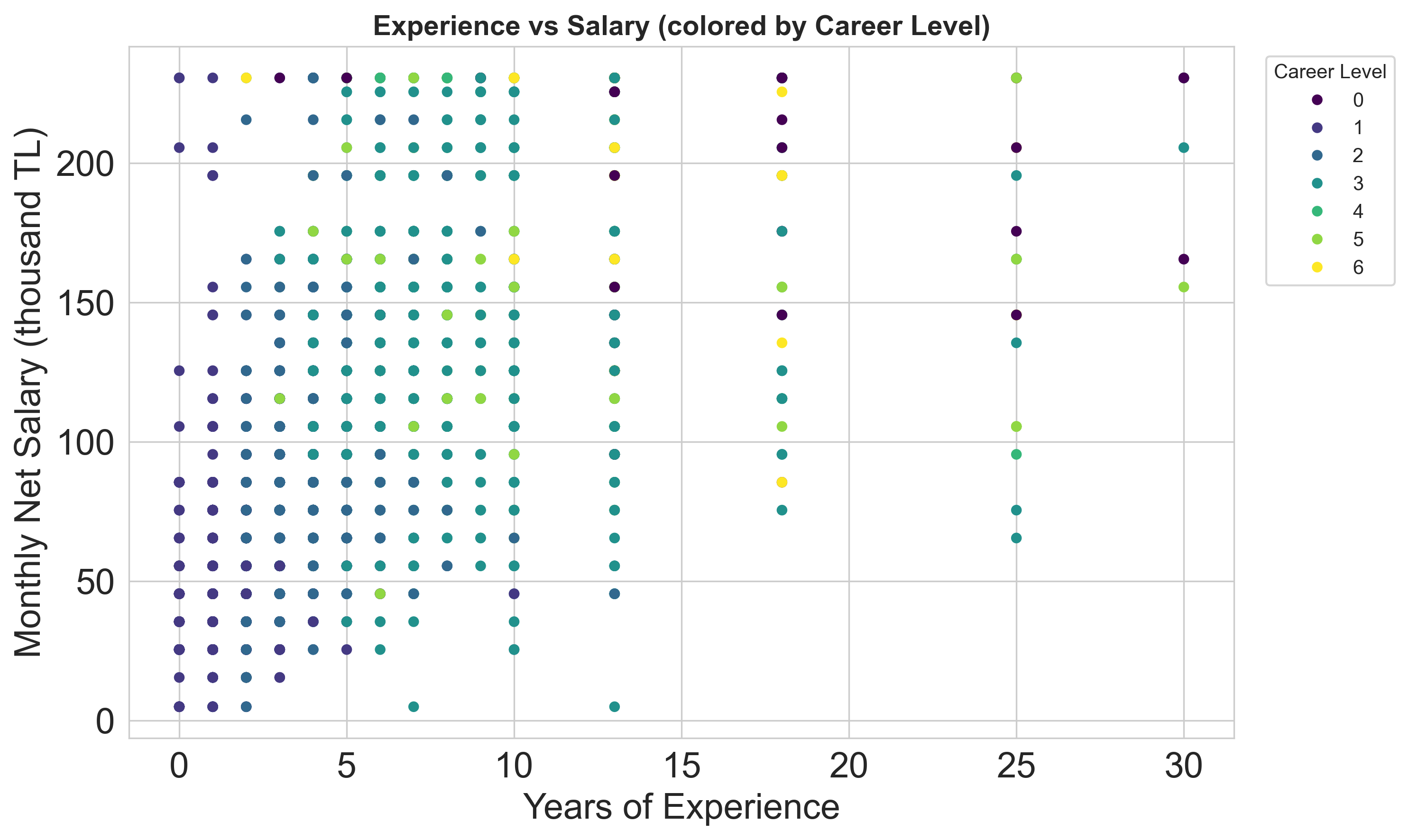
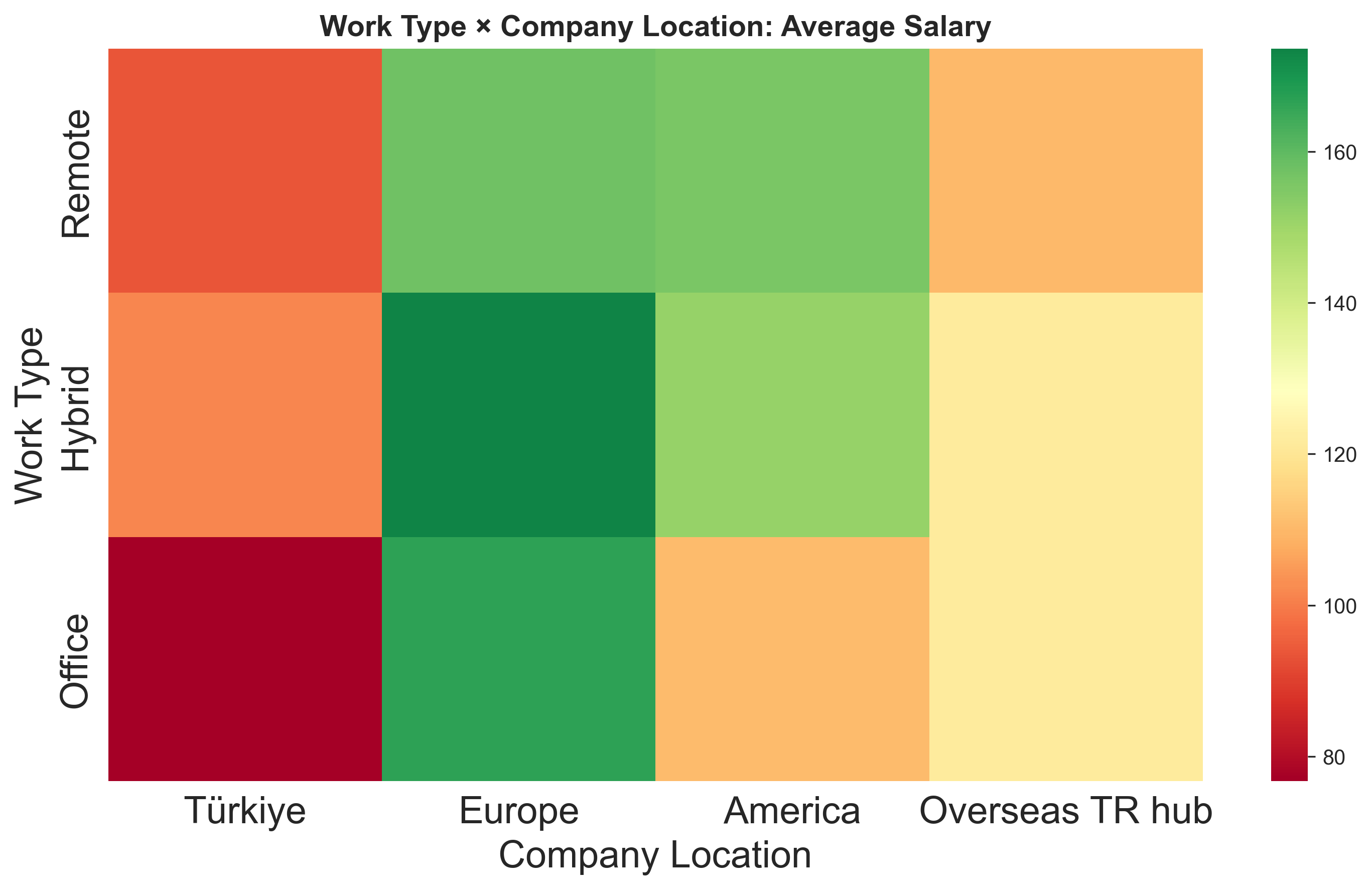
Not: Bu heatmap, çalışma şekli ve şirket lokasyonu kombinasyonlarında Ortalama Maaş dağılımını gösterir; Office kombinasyonlarının Remote ve Hybrid’e göre belirgin şekilde daha düşük seyrettiği görülür.
Etkileşimli Bileşenler
- Box plots (lokasyon/seviye/çalışma biçimi) ve kariyer akışı (Sankey) gibi etkileşimli örnekler üretildi. Blog içinde temsilî görselleri paylaşıyorum; etkileşimli sürümler sitede gömülü olarak sunulabilir.
Bağlantılar
- GitHub repo: salary_analysis_project
- Canlı interaktif dashboard: maas-anketi.streamlit.app
Kullandığım Araçlar
- Python, pandas, numpy, scipy, seaborn, matplotlib, plotly, streamlit
Hızlı Başlangıç (İsterseniz Yerelde Deneyin)
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
# Örnek kod bloklarını doğrudan bir notebook veya Python oturumunda çalıştırabilirsiniz.
jupyter notebook
Kodu ile Yeniden Üret (Seçme Parçalar)
Aşağıdaki örnekler, repodaki betiklerin sadeleştirilmiş birer özetidir. Tam akış için src/ ve notebooks/ klasörlerine bakabilirsiniz.
1) Veri Yükleme ve Basit Temizleme
import pandas as pd
df = pd.read_csv("anket.csv") # Tek birleştirilmiş CSV kullanın (örnek)
# Örnek: kolon adlarını standardize etme
df.columns = (
df.columns.str.strip().str.lower()
.str.replace(" ", "_", regex=False)
.str.replace("-", "_", regex=False)
)
# Örnek: Ortalama Maaş (salary_numeric) üretimi
if "salary_numeric" not in df:
# Örnek: salary_range "61-70" → 65.5, "300+" → 350
rng = df.get("salary_range")
if rng is not None:
import re
def midpoint(v):
if pd.isna(v):
return pd.NA
s = str(v)
m = re.match(r"^(\d+)-(\d+)$", s)
if m:
a, b = map(float, m.groups())
return (a + b) / 2
m2 = re.match(r"^(\d+)\+$", s)
if m2:
return 350.0
try:
return float(s)
except ValueError:
return pd.NA
df["salary_numeric"] = rng.map(midpoint)
df = df.dropna(subset=["salary_numeric"]).query("salary_numeric > 0")
2) İstatistiksel Karşılaştırma (Ör. Kıdem Grupları)
import numpy as np
from scipy import stats
# Seviye grupları arasında Ortalama Maaş farkını test edelim
groups = [g["salary_numeric"].values for _, g in df.groupby("seniority", dropna=True)]
# Normallik/varyans varsayımı belirsiz ise Kruskal-Wallis anlamlı bir alternatif
stat, p = stats.kruskal(*groups)
result = {"test": "kruskal", "stat": float(stat), "p_value": float(p)}
result
3) Görselleştirme (Seaborn ve Plotly)
import seaborn as sns
import matplotlib.pyplot as plt
# Seaborn: seviyeye göre Ortalama Maaş boxplot
plt.figure(figsize=(8, 5))
sns.boxplot(data=df, x="seniority", y="salary_numeric")
plt.tight_layout()
plt.show()
# Plotly: etkileşimli boxplot (lokasyona göre)
import plotly.express as px
fig = px.box(df, x="company_location", y="salary_numeric", points=False)
fig.show()
4) Basit ROI Yaklaşımı (Teknoloji/araç kullanımına göre)
# Varsayım: her satırda kullanılan belli araç/teknoloji için işaret (1/0) kolonları var
# Örnek bir araç kolonu: "uses_dbt" veya "uses_react" gibi
feature = "uses_react" # örnek kolon adı
if feature in df:
roi_df = (
df.assign(feature=df[feature].fillna(0).astype(int))
.groupby("feature")["salary_numeric"].mean()
.rename(index={0: "kullanmayan", 1: "kullanan"})
.to_frame("avg_salary")
)
roi_df["delta_vs_not"] = roi_df["avg_salary"] - roi_df.loc["kullanmayan", "avg_salary"]
print(roi_df)
5) Mini Streamlit Uygulaması (Seçimlere göre box plot)
Not: Tam özellikli sürüm için src/streamlit_dashboard.py dosyasındaki dashboard'u kullanabilirsiniz.
import streamlit as st
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
st.set_page_config(page_title="2025 Salary Analysis — Mini", layout="wide")
uploaded = st.file_uploader("Birleştirilmiş anket CSV yükleyin", type=["csv"])
if uploaded is not None:
df = pd.read_csv(uploaded)
df.columns = df.columns.str.strip().str.lower().str.replace(" ", "_", regex=False).str.replace("-", "_", regex=False)
if "salary_numeric" not in df and "salary_range" in df:
import re
def midpoint(v):
if pd.isna(v):
return pd.NA
s = str(v)
m = re.match(r"^(\d+)-(\d+)$", s)
if m:
a, b = map(float, m.groups())
return (a + b) / 2
m2 = re.match(r"^(\d+)\+$", s)
if m2:
return 350.0
try:
return float(s)
except ValueError:
return pd.NA
df["salary_numeric"] = df["salary_range"].map(midpoint)
df = df.dropna(subset=["salary_numeric"]).query("salary_numeric > 0")
# Blog örneğinde seviye olarak ya kategorik "seniority" ya da sayısal ölçek "seniority_level_ic" bulunabilir
level_col = "seniority" if "seniority" in df.columns else ("seniority_level_ic" if "seniority_level_ic" in df.columns else None)
seniority_opts = ["(hepsi)"] + (sorted([s for s in df[level_col].dropna().unique()]) if level_col else [])
workmode_opts = ["(hepsi)"] + sorted([s for s in df.get("work_mode", pd.Series(dtype=str)).dropna().unique()])
col1, col2 = st.columns(2)
with col1:
sel_seniority = st.selectbox("Seviye", seniority_opts)
with col2:
sel_workmode = st.selectbox("Çalışma Biçimi", workmode_opts)
filtered = df.copy()
if sel_seniority != "(hepsi)" and level_col:
filtered = filtered[filtered[level_col] == sel_seniority]
if sel_workmode != "(hepsi)" and "work_mode" in filtered:
filtered = filtered[filtered["work_mode"] == sel_workmode]
st.write(f"Kayıt sayısı: {len(filtered):,}")
fig, ax = plt.subplots(figsize=(8, 5))
sns.boxplot(data=filtered, x=(level_col or "seniority"), y="salary_numeric", ax=ax)
st.pyplot(fig)
else:
st.info("Başlamak için CSV yükleyin.")
İstatistiksel Testler ve Yorumlama İlkeleri
- Varsayımlar (normallik/varyans homojenliği) ihlali durumunda sağlam (robust) alternatifler kullanıldı.
- Çoklu karşılaştırmalarda yalancı pozitifleri azaltmak için düzeltmeler uygulandı (gerekli yerlerde).
- Sonuçlar yalnızca korelasyon değil, nedensellik iddiası taşımayan ilişkiler olarak yorumlandı.
Karşılaşılan Problemler ve Çözümler
-
Kategori Standardizasyonu: Farklı yazımlarla gelen rol/seviye/konum etiketleri analizde gürültü oluşturdu.
Çözüm: Özel eşleme sözlükleri ile birleşik etiketler; düşük frekanslı kategorileri "Diğer" altında toplama. -
Ücret Birim Uyumsuzluğu: Aylık/yıllık/saatlik beyanlar karışıktı.
Çözüm: Tüm beyanları saatlik ücrete normalize eden açık formüller; uç değeri winsorize veya kantil kırpma ile sınırlama. -
Dengesiz Sınıflar: Bazı rollerde örnek sayısı düşüktü.
Çözüm: Parametrik olmayan testler (Kruskal-Wallis), etkibüyüklüğü odaklı yorum ve güven aralıkları. -
Karıştırıcı Değişkenler: Rol/kıdem/lokasyon etkileri üst üste biniyordu.
Çözüm: Parçalı karşılaştırmalar; gerektiğinde çoklu değişkenli kontrollü kıyas.
Kıdem Modelleme Notu (IC vs Managerial/Ownership)
Anketin “Hangi seviyedesin?” yanıtları tek bir sıralı yapı içinde değerlendirilemeyecek kadar farklı türden rolleri içerdiği için öncelikle iki ana kategori tanımlandı: Individual Contributor (IC) ve Managerial/Ownership.
- IC: Junior, Mid, Senior, Staff Engineer, Team Lead, Architect
- Managerial/Ownership: Engineering Manager, Director Level Manager, C-Level Manager, Partner
IC seviyeleri ordinal değişken olarak yeniden kodlandı: Junior=1, Mid=2, Senior=3, Staff Engineer=4, Team Lead=5, Architect=6. Böylece kıdem ile maaş ilişkisi doğrudan incelenebilir hale geldi.
Managerial/Ownership rolleri ise doğası gereği ordinal değil, kategorik değişken olarak ele alındı; Engineering Manager, Director, C-Level, Partner için ayrı kategoriler tanımlandı ve One-Hot encoding uygulandı. Ek olarak is_manager ikili değişkeni tanımlanarak yönetim/sahiplik rolü basitçe işaretlendi.
Raporlamada IC seviyeleri tek bir ordinal eksende gösterildi; yönetim ve sahiplik rollerinin dağılımları ise ayrı kategorik karşılaştırmalarla sunuldu.
Çalışan Lokasyonu Tahmini (Heuristik)
Çalışan lokasyonu, şirket lokasyonu ve çalışma şekline dayanarak tahmin edilmektedir; %100 doğruluk garantisi yoktur.
Kurallar:
- Şirket Lokasyon ∈ {Türkiye, Avrupa, Amerika}
- Çalışma Şekli = Office → 1
- Çalışma Şekli = Hybrid → 1
- Çalışma Şekli = Remote → 0
- Şirket Lokasyon = "Yurtdışı TR hub" ve Çalışma Şekli = Remote → 0 (Türkiye’de olabilir ama net değil)
- Şirket Lokasyon = "Yurtdışı TR hub" ve Çalışma Şekli ∈ {Hybrid, Office} → 0 (aykırı değer; dışarıda bırak)
Not: “Yurtdışı TR hub” değeri, “is likely company location” değerlendirmesinden çıkarılmıştır.
Kolon İsimleri ve Kodlama Kuralları
Temizlenmiş kolon isimleri, boşlukların alt çizgi ile değiştirilmesi ve Türkçe karakterlerin latinize edilmesi prensibine göre güncellenmiştir. Örnekler (güncel):
management_Staff_Engineerrole_SAP_Developerprogramming_Objective_Ccompany_location_Yurtdisi_TR_hub
Bu yaklaşım hem okunabilirliği korur hem de kod tarafında güvenli ve tutarlı erişim sağlar.
Gelecek Çalışma
- Ücret tahmini için düzenli regresyon (Ridge/Lasso) ve ağaç tabanlı modellerle karşılaştırmalı deneyler
- Bayesçi modelleme ile belirsizlik tahmini
- Daha fazla anket dalgası ile zaman serisi eğilim analizi
- Öznitelik mühendisliği: rol-araç eşleşmelerinden etkileşim terimleri
İletişim
Bu yazı tek sayfalık bir brifing olarak hazırlandı; daha fazla detay görmek isteyenler GitHub reposuna göz atabilir. Sorular/öneriler için bana ulaşabilirsiniz.